In partnership with

Free email without sacrificing your privacy

Gmail is free, but you pay with your data. Proton Mail is different.
We don’t scan your messages. We don’t sell your behavior. We don’t follow you across the internet.
Proton Mail gives you full-featured, private email without surveillance or creepy profiling. It’s email that respects your time, your attention, and your boundaries.
Email doesn’t have to cost your privacy.

🕸️💥 Interesting Tech Fact:
Few people know that one of the earliest moments the Internet’s fragility was publicly exposed happened in 1980, when a tiny programming error in ARPANET’s routing tables caused the entire network—then the backbone of global research communications—to crash repeatedly for hours, marking the first recorded internet-scale outage. The bug, known as the “Interface Message Processor Lockup,” was triggered by a single corrupted router update that propagated across the network, proving long before today’s cloud-era failures that even a young internet could collapse from an internal glitch rather than an attack ⚙️🔍. This obscure event quietly shaped the future of digital infrastructure, inspiring early redundancy models and giving rise to the concept of “network resilience” decades before it became a cybersecurity buzzword 🌐✨

Introduction
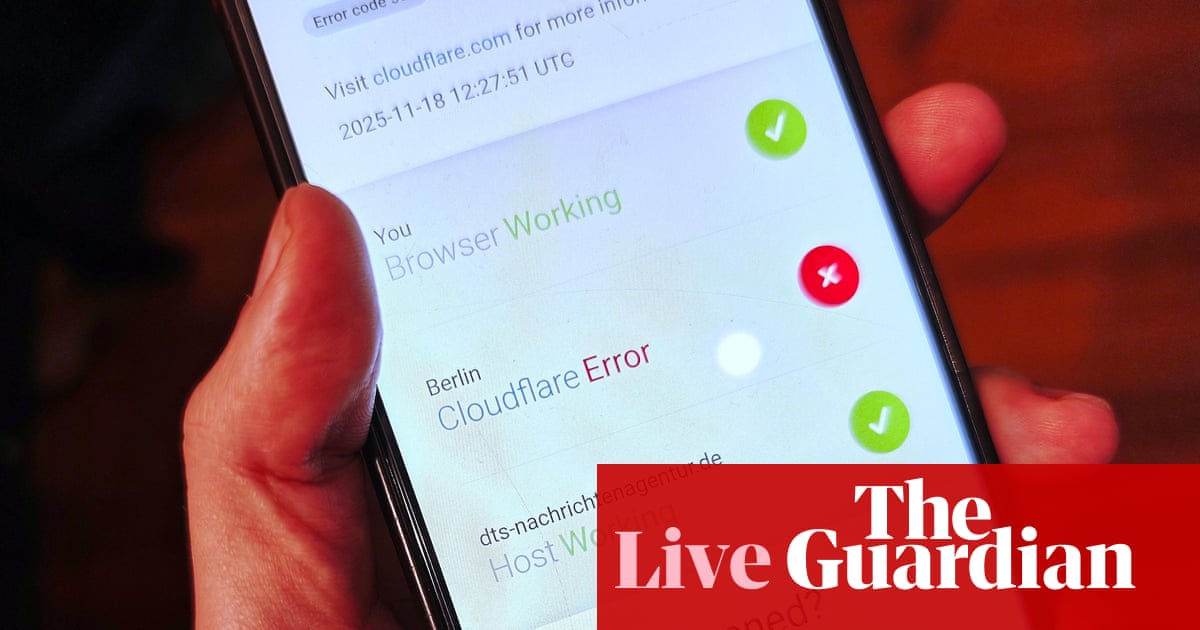
On November 18, 2025, a major global disruption rippled across the internet. Cloudflare — a company that quietly powers, protects, and speeds up a staggering portion of web traffic — suffered an internal failure that left high-profile platforms like ChatGPT, X (formerly Twitter), Spotify, and Canva intermittently unreachable. The culprit was not an external hacker or a sophisticated state-sponsored campaign, but rather a latent software bug triggered by an unexpectedly large configuration file tied to Cloudflare’s bot management system. In short, the backbone of the internet briefly faltered, offering a stark reminder of how concentrated and fragile its infrastructure remains.
This outage was more than a technical hiccup. It was a wake-up call about risk, dependency, and the implicit trust that billions of users—and countless companies—place in a few key gatekeepers. What happened on Nov 18 shines a spotlight on foundational cyber-resilience issues that rarely make headlines: not just how secure or performant our critical systems are, but how built-in assumptions and single points of failure can cascade into massive outages.

What Happened: Incident Recap and Impact
The disruption began around 6:20 AM ET (11:20 UTC), when Cloudflare reported a “spike in unusual traffic” to one of its internal services. Within minutes, users across multiple continents encountered widespread 500 Internal Server Errors when trying to access services relying on Cloudflare. By mid-morning, the company had deployed a fix, and by roughly 14:42 UTC, it declared the incident resolved, while continuing to monitor for residual instability.
The footprint of the outage was massive. High-traffic platforms like ChatGPT, X, Spotify, Canva, and even public services like the New Jersey Transit Authority or enterprise portals relying on Cloudflare’s infrastructure reported errors or complete inaccessibility. Given that Cloudflare routes about 20% of global web traffic, the disruption knocked out or degraded services used by millions.
Importantly, Cloudflare emphasized that no malicious activity was detected: this was not a DDoS attack or breach, but an internal system failure. The root cause was traced to a configuration file — part of its bot-mitigation architecture — that ballooned in size beyond normal operating parameters, crashing critical components.
Root Cause: Software Bug, Not Cyber Attack
In a statement following the incident, Cloudflare’s CTO, Dane Knecht, described the error as a “latent bug” in a subsystem that handles bot detection and threat traffic. The problem stemmed from a change in database permissions, which caused the bot-management system to generate a “feature file” with far more entries than expected. That oversized file was then distributed across Cloudflare’s global edge network, overwhelming the service and triggering a cascading failure.
Crucially, Cloudflare reiterated that there was no sign of external threat actors: this wasn’t an exploit, but an internal mis-calculation. As Knecht put it, “this was not an attack.” Still, the company expressed regret. In his message, he acknowledged that Cloudflare “failed its customers and the broader internet,” vowing a deep post-mortem and engineering changes to prevent recurrence.

Broader Implications: Centralization & Concentration Risk
This outage underscores a systemic risk in modern internet architecture: too much power centralized in too few hands. Cloudflare isn’t just a content delivery network (CDN); it’s a security layer, a global network of edge servers, a traffic router, a point of TLS termination, and a bot manager. Many companies lean on it for multiple critical functions simultaneously.
Because of that coupling, a single internal failure can ripple outward, taking down seemingly unrelated services. When Cloudflare’s edge layer failed, it didn’t matter if a company’s own origin server was healthy — the traffic couldn’t even reach it.
Experts observing the outage pointed out that such concentration risk isn’t hypothetical. Prof. Alan Woodward, a cybersecurity researcher, called Cloudflare a “gatekeeper” for the web: when it stumbles, the effects are felt widely and instantly. This ties into broader debates about resilience: how many organizations rely on a single backbone provider, and what happens when that provider fails?
Operational Risk vs. Threat Risk: A Different Kind of Cyber Risk
Often, cyber risk conversations focus on external threats: nation-state hackers, ransomware, phishing, or DDoS. But the Nov 18 Cloudflare outage illustrates that operational risk — internal bugs, configuration drift, or architectural assumptions — can be just as disruptive and dangerous.
Here are five action-oriented lessons that security, engineering, and leadership teams should take seriously:
Map critical dependencies: Understand which services, APIs, or customer-facing apps rely on third-party infrastructure like Cloudflare. Know not just that you use them, but how deeply — for DNS, CDN, WAF, bot management, etc.
Build redundancy: Don’t rely on a single provider for all aspects of traffic and security. Consider multi-CDN architectures, failover systems, or alternate routing strategies to mitigate single-vendor failures.
Embed operational failure in playbooks: Include large-scale provider outages (not just cyber attacks) in your incident response exercises. Simulate what happens if Cloudflare or a similar vendor goes down.
Demand transparency: Push critical vendors to publish detailed post-mortems after incidents. Understand what went wrong, how they fixed it, and what safeguards they’re putting in place.
Cultivate vendor relationships: Maintain open lines of communication with infrastructure providers. Ask about their internal resilience, their processes for updates, their rollback plans, and how they detect and mitigate latent failures.

Lessons for Cyber Resilience
The outage doesn’t just invite reflection — it forces action. For CISOs, security architects, and operational leaders, it’s time to reassess assumptions. Here’s what this teaches us about strengthening cyber resilience in light of core infrastructure risk:
Design for “fail-closed, but fallback allowed”: Security systems often default to “deny if uncertain.” But when your protective layer (like a bot manager or WAF) fails, you risk locking out legitimate users. Systems should gracefully degrade rather than catastrophically fail.
Test your third-party resiliency: It’s not enough to trust a vendor because they’re “big and stable.” You need to validate how they behave when things go wrong — through fault-injection testing, stress tests, or redundancy drills.
Prioritize transparency in SLAs: Contracts with infrastructure providers should explicitly cover failure modes, incident reporting, root-cause disclosure, and even compensation for wide-scale outages.
Invest in observability and telemetry: For your own systems, ensure you can detect when third-party systems degrade. Set up monitoring for upstream failures, latency spikes, or traffic anomalies — so you can react before they cascade into larger issues.
Align risk appetite across org: Not all teams think about infrastructure the same way. Security people worry about attacks; product teams worry about UX; executives worry about brand. Use incident learning to align on shared risk goals and resilience targets.

Final Thought
The Nov 18 Cloudflare outage was more than a headline — it was a vivid demonstration of how delicate and interconnected the backbone of the internet has become. For all its sophistication, the modern internet still rides on a handful of key players. And when one stumbles, the impact reverberates far beyond its own network.
This isn’t just a Cloudflare problem. It’s an Internet problem.
As organizations, we need to reckon with that reality. We must reduce dependency, demand accountability, and embed resilience into our systems — not as an afterthought, but as a core principle. The consequences of complacency are not hypothetical: they are real, immediate, and felt by millions when the lights go out.
In the era of AI, streaming, and instant global communication, our digital infrastructure needs to be as resilient as it is fast. November 18 may have been a “whoops” moment for one company, but for the rest of us, it’s a warning. Build like there will be more outages. Design like dependencies matter. And prepare like the backbone of the internet rests partly in your hands — because, in a world of shared infrastructure, in many ways, it does.
Subscribe to CyberLens
Cybersecurity isn’t just about firewalls and patches anymore — it’s about understanding the invisible attack surfaces hiding inside the tools we trust.
CyberLens brings you deep-dive analysis on cutting-edge cyber threats like model inversion, AI poisoning, and post-quantum vulnerabilities — written for professionals who can’t afford to be a step behind.
📩 Subscribe to The CyberLens Newsletter today and Stay Ahead of the Attacks you can’t yet see.

Further Reading